There are significant limitations to the implementation of Workflow processing in OWB 10g r1 and prior. There are methods available to developers that can add at least some amount of logic and conditionals such that it might be able to behave like an application. This section will enumerate how to use the facilities in OWB currently to build an IF/ELSE workflow pattern and a CASE workflow pattern.
One might ask, why use the tool for this particular processing pattern when it was not originally intended to operate as such? In a new BI environment there is a significant need to simplify the tools for developing the BI solution. Standardizing on one development tool and one platform has certain “soft” benefits in terms of project staffing, training, maintenance, extension. Why recruit and train developer on multiple tools and packages when one package provides 95% of the requirements and the remaining 5% can be accomplished with some “creative” application of the general tools available? Encapsulating nearly all application work into the OWB repository has significant benefit in regards to change management, metadata maintenance, and minimizing TCO by consolidating the development environment for BI to one tool.
OWB developers are anxious for improvements in upcoming releases of OWB. Engineers know you can never “wait for the perpetual next version” and while we all look forward to the improvements in future versions we need to be able to meet our project requirements with what we have today. Knowing some projects need standardization on OWB for lower TCO of BI we must be able to accomplish it with current versions.
Accomplishing and IF/ELSE and CASE workflow pattern is contingent on the ability of OWB to do the following:
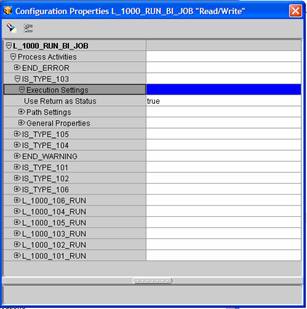
Use the return value of that function as the “Status”. Flow developers in OWB are very familiar with the Success/Error/Warning flows that all OWB WF activities have and are the flow control for changing execution paths. When this configuration setting is on the function or procedure must return a type NUMBER and one of the follow three values (1 = SUCCESS, 2 = WARNING, 3 = ERROR).
CASE PATTERN :
A classic example of the need for dispatching is as it relates to a Job Management System. Nearly all OWB projects require the ability toexecuteseveral process flows and mappings in an orchestrated fashion to produce their end result: data transformed and loaded. These systems might have severaldifferent types ofjobs they might need to execute, each requiring a different set of process flows and mappings.The CASE pattern isa common way to handle this need to dispatch a job to the correspondingprocess flow that will execute and accomplish the job.
In pseudo-code, the logic would look like:
CASE
WHEN JOB_TYPE = 101 THEN EXECUTE_101;
WHEN JOB_TYPE = 102 THEN EXECUTE_102;
DEFAULT THEN ERROR (should always be a known job type)
END CASE
Consider the following diagram in the OWB process flow GUI. Those familiar with OWB will recognize the PROCESS FLOW and TRANSFORMATION operators used to accomplish the pattern.
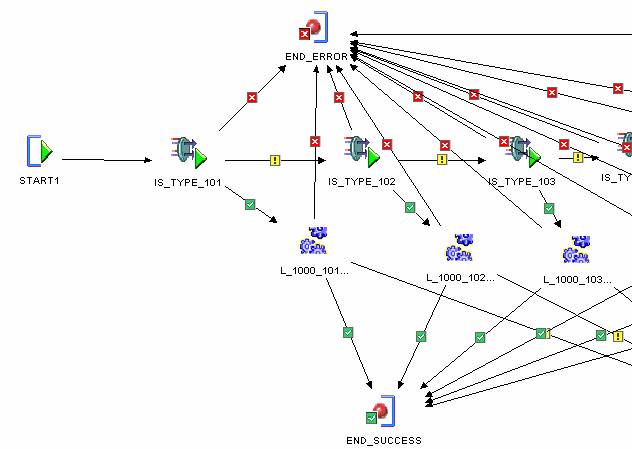
A custom function (IS_JOB_TYPE) is built to check the job type of the currently running job, and return a 1 if the job type matches the parameter. This indicates that the current running job is of the specified type and the system should execute the process flow that corresponds to that type. In the above example the job will be checked if it is 101. If it is not, then it proceeds to the check if it is 102, etc. If it is it proceeds to the workflow designated for that job type (102 say) and continues. Note: the transformation MUST be configured as previously mentioned in the configure portion of the OWB GUI or else it will not dispatch according to return value, but rather dispatch according to the successful running of the PL/SQL. The PL/SQL will almost always “run” sucessfully so this ends up nearly always choosing the “SUCCESS” branch.
The PROCESSFLOW is all the logic for a particular job type, and is the “body” of what you want to do for the CASE PATTERN.
Having explained the more detailed CASE pattern, one can easily see how it might be used to build a simple IF/ELSE pattern using the configuration already mentioned…