UPDATE: This step is available in Kettle 3.2 M1.
For those that have done more involved Kettle projects you’ll know how valuable the Javascript step is. It’s the Swiss Army knife of Kettle development. The calculator step is a nice thought, but the limited set of functions and the constriction of having to enter it in pulldowns can make more complex calculations more difficult.
Those that have done “observed metric” type calculations in Kettle will know this bit of Javascript well:
var prevRow;
var PREV_ORDER_DATE;if ( prevRow != null && prevRow.getInteger(“customernumber”, -1) == customernumber.getInteger() )
PREV_ORDER_DATE = prevRow.getDate(“orderdate”, null);
else
PREV_ORDER_DATE = null;prevRow = row.Clone();
This little bit of Javascript allowed you to “look forward” (or back depending on your sorting) and calculate the difference between items:
-
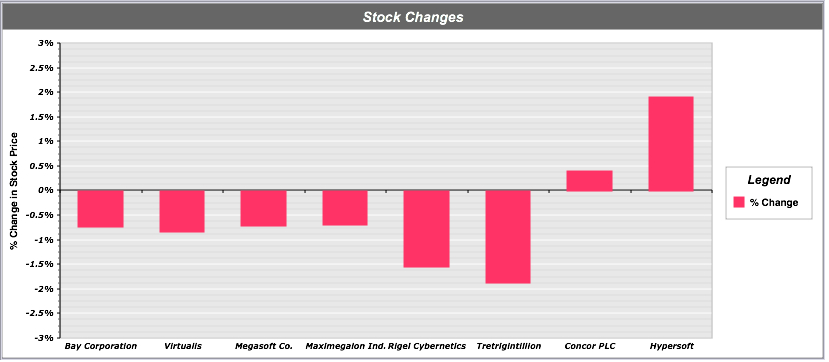
Watching a set of “balances” fly by and calculate the transactions (this balance – prev balance) = transaction amount
Web Page duration (next click time – this click time) = time spent viewing this web page
Order Status time (next order status time – this order status time) = Amount of time spent in this order status (warehouse waiting)
In other words, lining data up and peaking ahead and backwards is a common analytic calculation. In Oracle/ANSI SQL, there’s a whole set of functions that perform these type of functions.
This week I committed to the Kettle 3.2x source code a step to perform the LEAD/LAG functions that I’ve had to hand write several times in Javascript. It’s been long overdue as I told Matt I designed the step in my head two years ago and he’s been patiently waiting for me to get off my *ss and do something about it.
You can find more information about the step on its Wiki page, along with a few examples in the samples/transformations/ directory.
The step allows you peek N rows forward, and N rows backward over a group and grab the value and include it in the current row. The step allows you to set the group (at which to reset the LEAD/LAG), and setup each function (Name, Subject, Type, N rows)
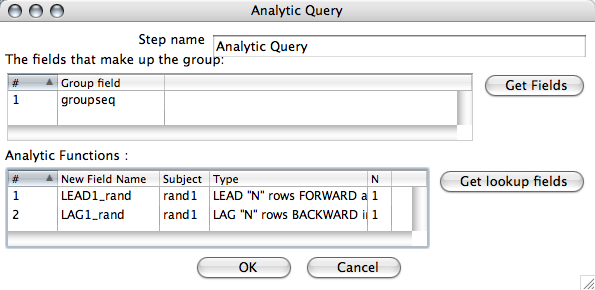
Using a group field (groupseq) and LEADing/LAGing ONE row (N = 1) we can get the following dataset:
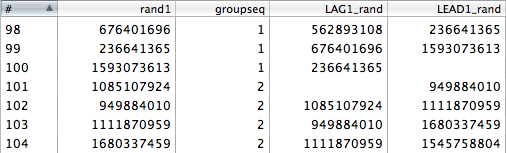
Any additional calculations (such as the difference, etc) can be calculated like any other fields.
This was my first commit to the Kettle project, and a very cool thing happened. I checked in the base step and in true open source fashion, Samatar (another dev) noticed, and created an icon for my step which was great since I had no idea what to make as the icon. Additionally, hours after my first commit he had included a French translation for the step. He and I didn’t discuss it ahead of time, or even know each other. That’s the way open source works… well. 🙂
RIP prevRow = row.clone(). You are dead to me now. Long live the Analytic Query step