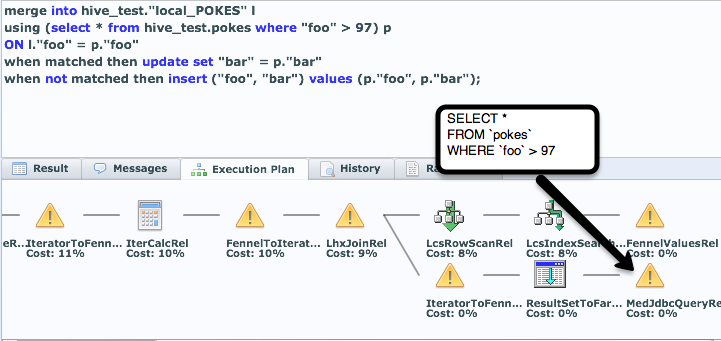
By far, the most popular way for PDI users to load data into LucidDB is to use the PDI Streaming Loader. The streaming loader is a native PDI step that:
- Enables high performance loading, directly over the network without the need for intermediate IO and shipping of data files.
- Lets users choose more interesting (from a DW perspective) loading type into tables. In particular, in addition to simple INSERTs it allows for MERGE (aka UPSERT) and also UPDATE. All done, in the same, bulk loader.
- Enables the metadata for the load to be managed, scheduled, and run in PDI.
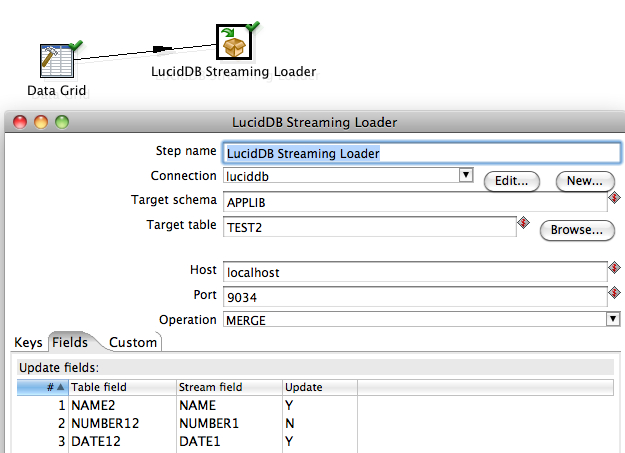
However, we’ve had some known issues. In fact, until PDI 4.2 GA and LucidDB 0.9.4 GA it’s pretty problematic unless you run through the process of patching LucidDB outlined on this page: Known Issues.
In some ways, we have to admit, that we released this piece of software too soon. Early and often comes with some risk, and many have felt the pain of some of the issues that have been discovered with the streaming loader.
In some ways, we’ve built an unnatural approach to loading for PDI: PDI wants to PUSH data into a database. LucidDB wants to PULL data from remote sources, with it’s integrated ELT and DML based approach (with connectors to databases, salesforce, etc). Our streaming loader “fakes” a pull data source, and allows PDI to “push” into it.
There’s mutliple threads involved, when exceptions happen users have received cruddy error messages such as “Broken Pipe” that are unhelpful at best, frustrating at worse. Most all of these contortions will have sorted themselves out and by the time 4.2 GA PDI and 0.9.4 GA of LucidDB are released the streaming loader should be working A-OK. Some users would just assume avoid the patch instructions above and have posed the question: In a general sense, if not the streaming loader how would I load data into LucidDB?
Again, LucidDB likes to “pull” data from remote sources. One of those is CSV files. Here’s a nice, easy, quick (30k r/s on my MacBook) method to load a million rows using PDI and LucidDB:
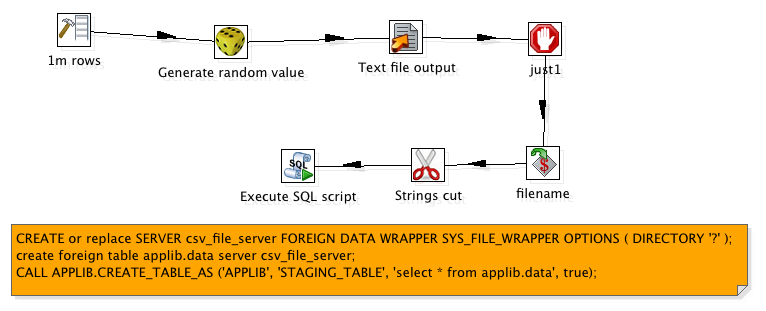
This transformation outputs to a Text File 1 million rows, waits for that to complete then proceeds to the load that data into a new table in LucidDB. Step by Step the LucidDB statements
— Points LucidDB to the directory with the just generated flat file
— LucidDB has some defaults, and we can “guess” the datatypes by scanning the file
CREATE or replace SERVER csv_file_server FOREIGN DATA WRAPPER SYS_FILE_WRAPPER OPTIONS ( DIRECTORY ‘?’ );
— Let’s create a foreign table for the data file (“DATA.txt”) that was output by PDI
>create foreign table applib.data server csv_file_server;
— Create a staging, and load the data from the flat file (select * from applib.data)
CALL APPLIB.CREATE_TABLE_AS (‘APPLIB’, ‘STAGING_TABLE’, ‘select * from applib.data’, true);
We hope to have the streaming loader ready to go in 0.9.4 (LucidDB) and 4.2 (PDI). Until then, consider this easy, straight forward method of loading data that’s high performance, proven, and stable for loading data from PDI into LucidDB.
Example file: csv_luciddb_load.ktr