Real time. Roland has built a cool Pentaho application that collects data from MySQL performance tables and metadata views and shows reports on this performance, errors, etc. Cool stuff for DBAs.
Picture, total crap from the mobile

Real time. Roland has built a cool Pentaho application that collects data from MySQL performance tables and metadata views and shows reports on this performance, errors, etc. Cool stuff for DBAs.
Picture, total crap from the mobile
I’m visiting a Pentaho customer right now whose current “transaction” volume is 200 million rows per day. Relatively speaking, this puts their planned warehouse in the top quintile of size. They will face significant issues with load times, data storage, processing reliability, etc. Kettle is the tool they selected and it is working really well. Distributed record processing using Kettle and a FOSS database is a classic case study for Martens scale out manifesto.
This organization doesn’t have unlimited budget. Specifically, they don’t have a telecom type budget for their telecom like volume of data. One of the issues that has come up with their implementation has been the tradeoff between space, and keeping the base level fact records. For example, at 200 million / day and X bytes per fact you start to get into terabytes of storage quickly. It was assumed, from the start of the project, only summary level data could be stored for any window of time exceeding 10 days or so.
The overall math is sound.
Size per record (S) x number of records per day (N) = size per day of data growth (D)
In this equation, there’s really not much we can do, if we want to keep the actual base level transaction, about the number of records per day. N becomes a fixed parameter in this equation. We do have some control over the S value, which is mostly about what this blog is about.
Can we reduce the size of S by such an amount that D becomes more realistic? The answer is the ARCHIVE engine in MySQL.
I created the DDL for a typical fact record. Few Dimension IDs and a few of numeric values.
CREATE TABLE test_archive
(
DIM1_ID INT
, DIM2_ID INT
, DIM3_ID INT
, DIM4_ID INT
, DIM5_ID INT
, NUMBER1 FLOAT
, NUMBER2 FLOAT
, NUMBER3 FLOAT
, NUMBER4 FLOAT
) engine=ARCHIVE
;
I did this in MyISAM as well
CREATE TABLE test_myisam
(
DIM1_ID INT
, DIM2_ID INT
, DIM3_ID INT
, DIM4_ID INT
, DIM5_ID INT
, NUMBER1 FLOAT
, NUMBER2 FLOAT
, NUMBER3 FLOAT
, NUMBER4 FLOAT
) engine=MyISAM
;
I used a simple Kettle transformation to populate both the these tables with 1 million rows of data. It wasn’t scientific but the INSERT performance of the Archive and MyISAM tables were very similar (within 10% of the throughput of rows).
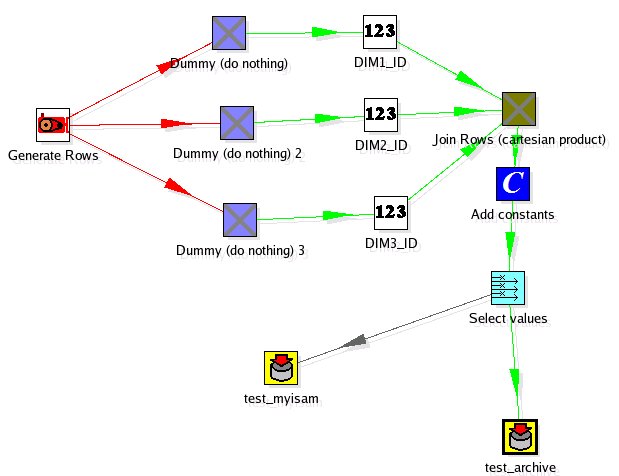
So now we have a million rows, with a reasonable FACT record format. How much space do these 1 million rows require to store?
+--------------+---------+---------------+------------+
| table_name | engine | total_size_mb | table_rows |
+--------------+---------+---------------+------------+
| test_archive | ARCHIVE | 2.63 | 1000000 |
| test_myisam | MyISAM | 36.24 | 1000000 |
+--------------+---------+---------------+------------+
The Archive table uses an order of magnitude LESS space to store the same set of FACTS. What about query performance? I’ll have to do another blog on a more scientific approach but the anecdotal query performance on typical OLAP queries (select sum() from fact group by dim1_id) seemed related (less than a 15% difference).
Let’s be clear here, one MUST have a good aggregate table strategy so the fact records are RARELY accessed because the performance will not rock your world. However, this is the case with these volumes anyhow. Summaries and Aggregates have to be built for the end user to have a good experience on the frond end.
Archive engine is strange. INSERT/SELECT only. You can’t do ANYTHING with it, except drop and recreate it. For historical fact loads on “settled” DW data segmented on a daily basis this is usually not an issue. No transactions need, no DML needed. I’d also like to see how this compares to “packed” MyISAM tables at some point. I’m guessing I wouldn’t expect to see it beat the compression in terms of storage space, but there’s some nice things you can do with MyISAM tables (for instance, MERGE).
Back of the napkin calculation to handle BIG data volume:
2.63 MB / million * 200 per day = 526 MB / day
526 MB / day * 365 days = 187.5 GB
Anyone else have fun experiences to share with the Archive engine?
Side Note: I did all this testing on a VNC Server enabled EC2 instance I use for testing. Fire it up, VNC in, do my testing, shut it down. I LOVE EC2!
One of my pet peeves is an email thread that grows 100 lines with every “Sounds good to me” reply. You know what I’m talking about.
10 screens of text, with about 1 screen of actual content/conversation.
All these logos and titles, fax numbers, clever logans and sayings, etc. AHHHH….
It’s a networked world, it doesn’t have to be on EVERY SINGLE EMAIL RESPONSE. If you want to get in touch with me, you can google me and immediately find my site, etc.
I’m Twitter’ed, LinkedIn, YahooMessenger, AIM, MSN, skype, etc. I’m easy to get a hold of, you don’t need to have 10 copies of ALL MY CONTACT INFO in an email.
There’s an intersection of value at
a) products that are web service and plugin enabled
b) companies that provide interesting “net effect” services
For instance, tonight my hosting provider, Dreamhost, emailed and said that my feed was being hit so extensively that I was causing service interruptions on the other accounts on the machine.
First, to the other sites, and I have no idea who you are but I’m sorry!
Second, I was able to leverage a web 2.0 – ish service and plugin to instantly alleviate the pain (with a cached redirected version of my feed) and now I’m getting some cool extra stats on my RSS (who/how/what). All in < 30 minutes.
Because my blogging software works in the networked world, things happen easier and more naturally than me having to hack around a bunch of code special scripting/patching on my website. Plugins/Service/etc. It’s a grand new world.
PS – I guess I’m over that whole “bloggers block” thing. Spouting out useless crap on my blog again.