Just in time for the Hadoop Summit, we’ve updated some pieces of LucidDB to be able to do “more” with the Hive driver. We’ve had the ability to connect and query data inside of Hive for about a year already. The initial implementation allowed people to:
- Use Hive for it’s massive scalability, distributed data processing capabilities.
Hive is great at processing huge amounts of data. It’s scales to hundreds of servers, and has a bunch of fantastic features for structured and semi structured data processing, fault tolerance, etc. Hive is a great way to do heavy lifting sorting through petabytes of data to arrive at some interesting, pre-aggregated datasets. - Cache the output of Hive views into LucidDB.
Now when we’re talking about taking the output of Hive views into LucidDB, we’re not talking about SMALL datasets (10k rows) we’re talking about 50 or 100, or 500 million rows. Some might think that number is small (by Hive standards it often is) and others might think that’s big (our entire DW is only 200 million rows). However, LucidDB has provided the ability to draw in data from Hive via easy MERGE/INSERT statements.
You can see some background on this integration that has been functional since August 2010 on Eigenpedia: http://pub.eigenbase.org/wiki/LucidDbHive
Also, a video I recorded last year showing the basic integration: (THIS IS NOT NEW!!!!).
Why the blog now? We’ve done a couple of things over the past while.
- We’ve done some work on LucidDB (yet to be committed and will be a POST 0.9.4 commit) that allows the use of Hives, well, somewhat unique driver. Hive’s driver has a bunch of quirks in terms of metadata, etc that we’re now recognizing and using properly over in LucidDB.
- We’ve updated to the 0.7.0 release. We’re now ready to go with the latest and great Hive features.
- We’ve enabled some pushdowns to work to allow for easier day to day loading of LucidDB tables from Hive, along with a limited workload of Ad Hoc SQL access.
Our vision for Big Data dictates the need for:
- Live, real time, per query access to the Big Data system that is useful and practical (ie, filters, etc).
This means that you need to be able to allow the user, via simple Parameter or simply by hitting a different schema or table access to the live data.

- Easy, full ANSI SQL access to high performance, low latency, aggregated data.
Dashboards need results that come back in seconds, not minutes. LucidDB and the data cached there provide a great “front end” for easily doing real BI work on top of data that sits inside Hive.
We’ve updated our connectors to allow some filtering/projection pushdowns to work with Hive.
Here’s a simple example. We have a report or dashboard which is looking for only a subset of data in Hive. We want to allow the filtering of data to occur and for Hive to receive the filtering from our OLAP/Dashboard.
By default LucidDB will read the entire table and do all SQL functions over in our
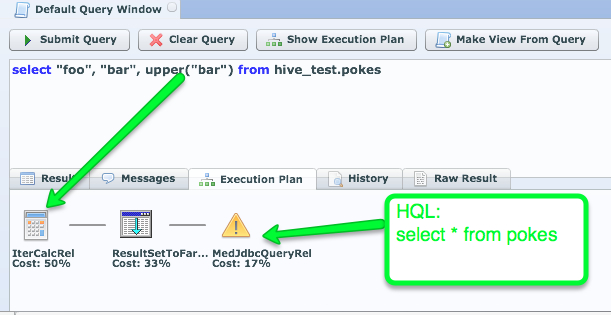
However, pulling over the entire table is really not going to work well for us. This would really be the worst of both worlds; you’d be better off just querying Hive directly. However, luckily we’ve enabled some pushdowns be pushed down to Hive.
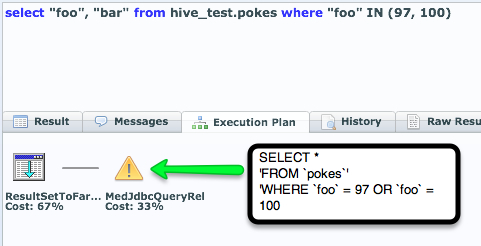
Notice that the condition IN( values ) is being pushed down to the remote Hive server.
Let’s try something a bit more complex!
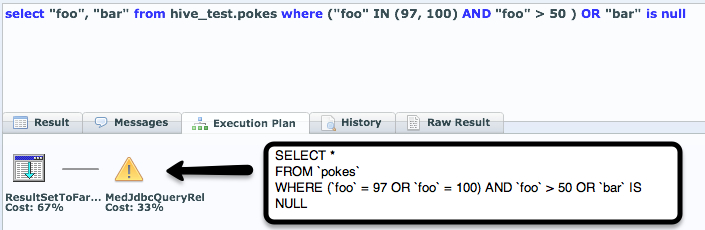
Currently, we’re able to push down most filters and projections.
Let’s take now take the use case where we’re trying to ONLY UPDATE records that have been updated since the last time we checked (ID > 97). More likely the key that we’d use to do this push down filter would be a date, but you can simply use your imagination.
Consider the following SQL:
merge into hive_test.”local_POKES” l
using (select * from hive_test.pokes where “foo” > 97)
ON l.”foo” = p.”foo”
when matched then update set “bar” = p.”bar”
when not matched then insert (“foo”, “bar”) values (p.”foo”, p.”bar”);
This SQL is a typical “incremental” load from a remote system. Syntactically a little dense, but it’s actually a VERY high performance method to load directly into LucidDB often eliminating the need entirely to draw the data through an intermediate server and process (ETL Tool).
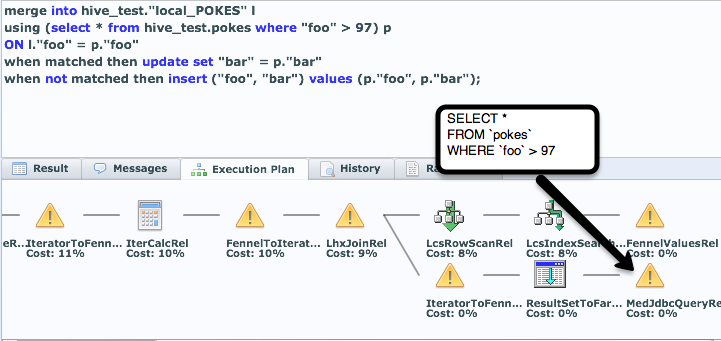
Our enhancements allow the Hive portion to be pushed down. Hive will ONLY return values greater than 97 and we’ll simply intelligently keep any changed records “up to date” in LucidDB for reporting.
Many of these changes will be in a patched version of LucidDB; we’ll make this patched release available to any customers who want these optimizations available, immediately for use with Hive. Let us know what you think by joining this conversation at the LucidDB forums: Hive Connector Pushdown
In a subsequent blog we’ll cover how to now match up data coming from Hive (or CouchDB) with data in other systems for reporting.
 I am currently making my way through the book,
I am currently making my way through the book,