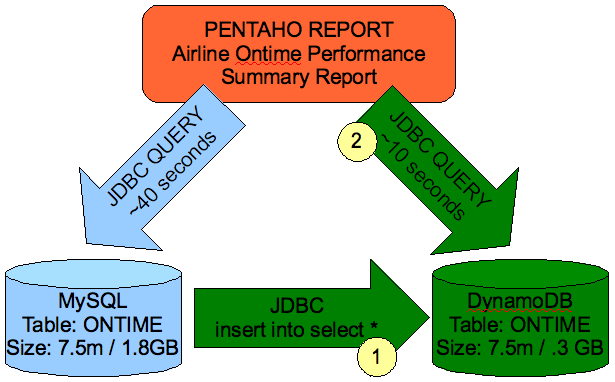
Here’s the scenario. You’ve got a table in MySQL for reporting that has a few million rows, and is denormalized for reporting. You’ve got a Pentaho Report that is querying this MySQL table. You have two problems with the current report.
- Your users are complaining that the query is slow, and they have to wait around for longer than they’d like to see their report. (approx 40s)
- Your DBAs are cranky because they see the size of this table is getting bigger. (approx 1.8GB)
MySQL is fundamentally designed to be an OLTP database and while it does a fantastic job at that, its data warehouse features were built as “bolt on” additions. Can it be used for BI? Absolutely, I’ve used it a many customer sites. Does DynamoDB provide a better set of features/capabilities for doing BI? We think so! Are they both 100% open source? You bet;why not choose the right tool for the right job then?
DynamoDB (aka LucidDB) is a “purpose built for BI” database. What does that mean? Well, I’ll be blogging about a lot of features that speak to our philosophy of a complete “BI Database” not just a fast one. One of the features that makes LucidDB complete, and not just a drag racer, is its ability to connect to remote data sources via JDBC and retrieve data. If you’re doing simple table replications, you don’t have to use an ETL tool, or do export or imports, or LOAD DATA INFILEs, etc. Our ability to connect to remote databases and access them as “remote tables” makes retrieving data into DynamoDB as easy as “insert into mytable select * from remote_table.”
Back to our original issue with our current MySQL
Our report is slow, and our database is big. How slow? Well, not really that bad, but at about 40s per query run that’s enough to tempt your business analyst to go fetch a coffee instead of continuing his work. How big? Well, not really that big, but at about 1.8GB it’s starting to get non trivial in terms of tuning the I/O etc.
Our goal is to improve both using DynamoDB; we’ll leave MySQL as our main OLTP application. We’re not trying to replace it – in fact, we’ll embrace MySQL as the system of record and simply “slurp/report” off this table in a separate reporting environment.
It’s a two step process.
- Connect from DynamoDB to MySQL using a JDBC connector, access the remote table, and draw over the data using a simple INSERT statement.
- Change our Pentaho Report to use the DynamoDB JDBC connector instead of MySQL.
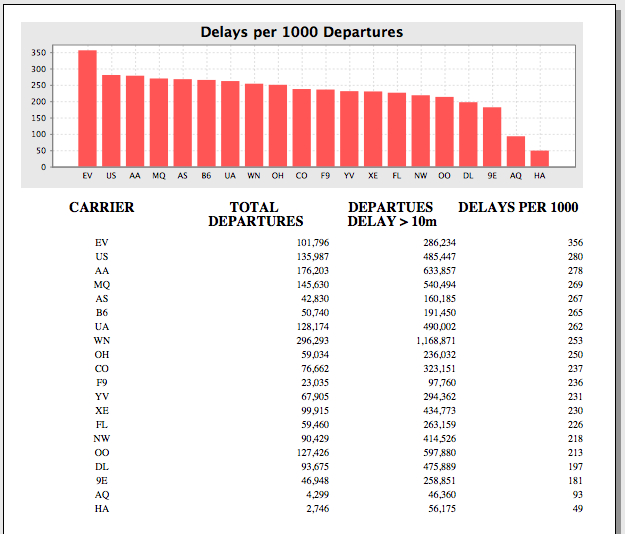
Our Pentaho Report is based on the following SQL
SELECT t.Carrier as “CARRIER”,
c as “C”, c2 as “C2”, c*1000/c2 as “C3” FROM
(SELECT Carrier, count(Carrier) AS c FROM ontime
WHERE DepDelay>10 GROUP BY Carrier) t JOIN
(SELECT Carrier, count(Carrier) AS c2 FROM ontime
GROUP BY Carrier) t2 ON (t.Carrier=t2.Carrier) ORDER BY c3 DESC;

This takes approximately 40s to run on MySQL database running the same machine.
Step 1: Connect, and load the data into our DynamoDB table.
— Create DynamoDB reporting table first
create schema faster;
create table faster.”ontime” (
“Year” int,
“Quarter” tinyint ,
“Month” tinyint ,
….. Abbreviated for Brevity ….
“Div5TailNum” varchar(10)
);
— Get access the MySQL table OnTime in the OTP schema on host localhost
create schema MYSQL_SOURCE;
set schema ‘MYSQL_SOURCE’;
CREATE SERVER MYSQL_REMOTE_SOURCE FOREIGN DATA WRAPPER
sys_jdbc OPTIONS (
driver_class ‘com.mysql.jdbc.Driver’,
url ‘jdbc:mysql://localhost/otp?useCursorFetch=true’,
user_name ‘root’,
password ‘easy’,
fetch_size ‘1000’,
table_types ‘TABLE’,
schema_name ‘otp’);
import foreign schema OTP from server MYSQL_REMOTE_SOURCE into MYSQL_SOURCE;
— Load DynamoDB table from MySQL database directly
insert into FASTER.”ontime” select * from MYSQL_SOURCE.”ontime”;
Notice that last statement. You don’t have to export to intermediate files, or use an ETL tool (not that that’s bad, I’m a big fan of ETL tools!). You can use good old fashioned SQL to get data from a remote database into DynamoDB.
Step 2: Change the Pentaho Report to use the new connection.
We open up our report and change our connection from MySQL
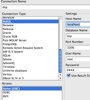
to DynamoDB
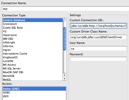
NOTE: Until we finish our QA’ed builds we’re using LucidDB driver instead of DynamoDB but they are, one and the same.
We make some minor adjustment to the SQL (quoting some tables/etc) and rerun our query and Voila, our report runs in 10s down from 40s, an improvement of 400%.
How about storage? Our storage report shows that DynamoDB is using only .3 GB to store the same 7 Million records as compared to MySQL at 1.8GB, or 1/6 of the storage.
Not a bad investment of a few minutes of time, I’d say. DynamoDB (LucidDB) takes just a few minutes to install, and because of its focus on BI you should find things like retrieving data from remote data sources easy, and effective. Let’s be truthful here as well; once you speed up a report by 400% and reduce its storage by 6x your boss will be calling you a dynamo.
Notes: Full set of scripts posted here: mysql_relief.zip. Original queries and dataset from Vadim at MySQLPerformanceBlog.
 At yesterdays Eigenbase Developer Meetup at SQLstream‘s offices in San Francisco we arrived at a new logo for LucidDB. DynamoBI is thrilled to have supported and funded the design contest to arrive at our new mascot. Over the coming months you’ll see the logo make it’s way out to the existing luciddb.org sites, wiki sites, etc. I’m really happy to have a logo that matches the nature of our database – BAD ASS!
At yesterdays Eigenbase Developer Meetup at SQLstream‘s offices in San Francisco we arrived at a new logo for LucidDB. DynamoBI is thrilled to have supported and funded the design contest to arrive at our new mascot. Over the coming months you’ll see the logo make it’s way out to the existing luciddb.org sites, wiki sites, etc. I’m really happy to have a logo that matches the nature of our database – BAD ASS!