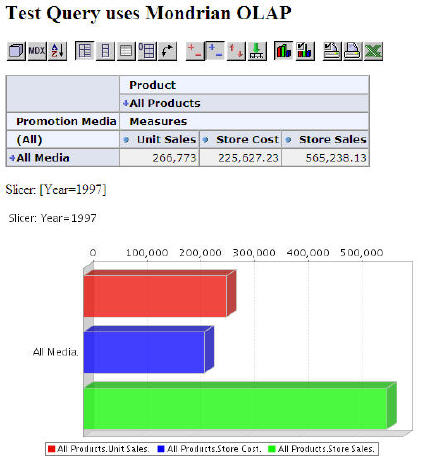
There was a posting on the OWB OTN forum about how to build a report documenting mappings, their sources, and their targets. Patrick Goessens provided an OMBPlus script that fits the bill and should work (perhaps slightly customized) brilliantly. I love OMBPlus and find it to be a very useful addition to the Oracle Warehouse Builder product. I’ve noticed Patricks postings before, and he is in the minority of OWB developers who have command of a very powerful feature.
There might be circumstances when OMBPlus might not be a prefereable option. Not everyone will have OWB installed, or want to pay the additional license costs to just “report” on the metadata. The consumer of this information might not be a “person,” but rather another system or repository. In that case, coordinating the execution of an OMBPlus script, parsing and importing into an alternative application might be troublesome.
I’ve built a small SQL script that runs against the OWB design repository public views (an Oracle provided view into the design metadata). I ran this against the solution for the sample company for my OWB workshop and it reports correctly for it. Use it as a reference, but ensure it works for your actual metadata repository as I don’t claim that this is a complete solution (or even nicely written SQL).
sqplus design_rep/design_rep_password@DB
select
distinct 'TARGET',
comp.map_name,
comp.data_entity_name,
comp.operator_type
from
all_iv_xform_map_components comp,
all_iv_xform_map_parameters param
where
lower(operator_type)
in ('table', 'view', 'dimension', 'cube')
and param.map_component_id = comp.map_component_id
and param.source_parameter_id is not null
UNION
select
distinct 'SOURCE',
t1.c1,
t1.c2,
t1.c3
from
(select
comp.map_name c1,
comp.data_entity_name c2,
comp.operator_type c3,
max(param.source_parameter_id) c4
from
all_iv_xform_map_components comp,
all_iv_xform_map_parameters param
where
lower(operator_type) in
('table', 'view', 'dimension', 'cube')
and param.map_component_id = comp.map_component_id
group by
comp.map_name, comp.data_entity_name, comp.operator_type) t1
where t1.c4 is null
order by 2,1
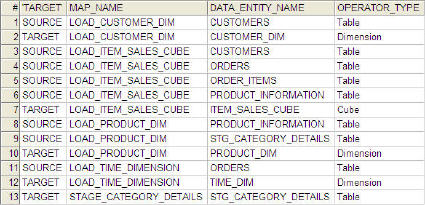
TARGETS are determined if any of their columns have a source parameter (ie, there’s been a line drawn into them on a mapping). SOURCES are determined if they do not have any source parameters (they don’t have any mapping lines coming “in”). I couldn’t see any special flag or marker to find the “one” target of a mapping, so it had to be inferred. I wonder if anyone from the OWB product team would like to comment on the validity of this logic?
Let me know how people get on with this script; especially if there’s any edge cases or revisions that augment it.