Following up on my previous blog about enabling SQL Access to CouchDB Views I thought I’d share what I think the single, biggest advantage is: The ability to connect, run of the mill, commodity BI tools to your big data system.
While the video below doesn’t show a PRPT it does show Pentaho doing Ad Hoc, drag and drop reporting on top of CouchDB with LucidDB in the middle, providing the connectivity and FULL SQL access to CouchDB. Once again, the overview:
BI Tools are commoditized; consider all the great alternatives available inexpensively (either in Open Source for free, Open Core, or even simply proprietary). Regardless of what solution you choose, these tools have fantastic, easy to use capabilities that are very easy for business users to build their own reports. After all, shouldn’t your developers be extending/creating new applications instead of fiddling with what filters your analysts/executives want to see on their dashboard?
Driving the developer out (as much as possible) is one of the best reasons to try and enable your cool, CouchDB views via SQL.
Here I’ll demonstrate, once we’ve connected LucidDB to our CouchDB view, how a BI Tool can:
- Easily see the data, and understand it’s datatypes. Metadata is well understood between SQL databases and BI tools.
- We can easily use a familiar query language, SQL, that allows for aggregation, filtering, and limiting. This gives a huge swath of BI tools the ability to talk to CouchDB.
- We translate the SQL we receive into optimized* RESTful HTTP view requests.
Per a reader suggestion here’s a video showing the solution, as opposed to the screenshots (PS – Let us know what you think about the CouchDB SQL access, or also the Video vs Screenshot approach).
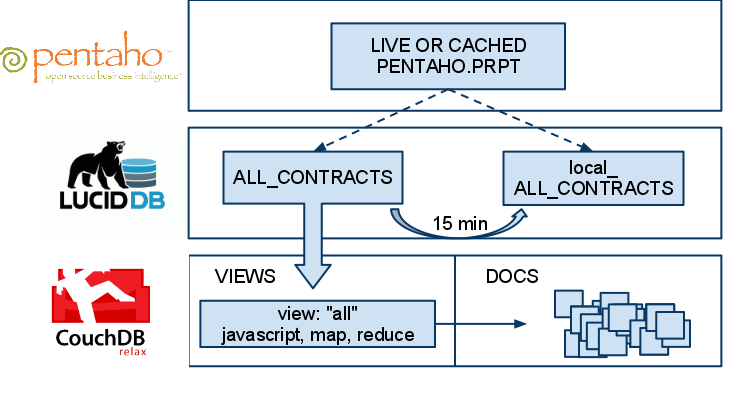
It picks up right after the previous section. Once we have that CouchDB view in LucidDB then Pentaho (or other BI tools) can connect and access, do ad hod reporting like they always have). As a certified database for Pentaho, you can be quite comfortable that Pentaho will work very very well with LucidDB.
PENTAHO does not even KNOW it’s talking to CouchDB -> It has NO idea; Pentaho thinks it’s a database just like any other
Without further delay:
*optimized = we have a few optimizations available to us, that we’ve not yet put into the connector. For instance, the ability to filter to a particular key (where key = XYZ) pushed down, or group_level=*. This will come over time as we enhance the connector. For now, we’re doing very little in terms of pushing down SQL filters/aggregations into the HTTP view. However, your view itself is almost CERTAINLY aggregated and doing this anyhow.
We’re keen on discussing with CouchDB/Hive/other Big Data users about their Ad Hoc and BI needs; please visit the forum thread about the connector.