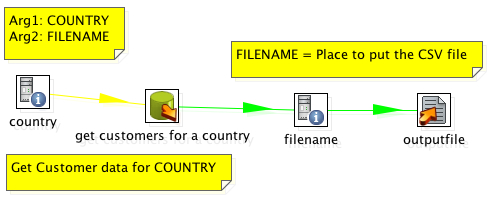
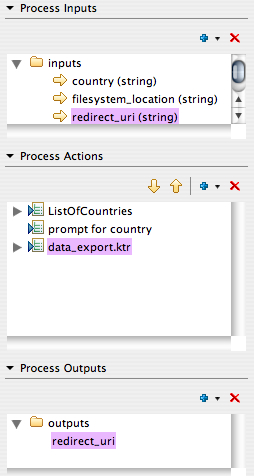
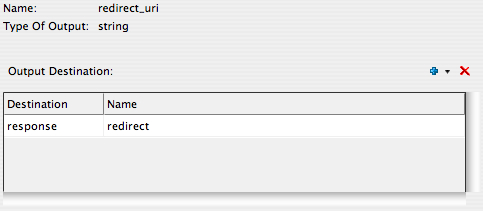
A couple of postings over the past few days that prompted me to put some digital pen to paper so to speak. The first was a post by L. Wayne Johnson who works for Pentaho who I had the pleasure to meet last week in Orlando entitled “Is it just sexy?” The second was by a Ted Cuzzillo over at datadoodle.com entitled “Tableau is the new Mac” Both share important perspectives that deserve some more light.
First, we have to start with a premise that leads you to see why there are two somewhat divergent paths that products/people/companies are taking. BI is now a commodity. The base technology components for doing BI (reports, dashboards, OLAP, ETL, scheduling, etc) is commodotized. Someone once told me that once Microsoft enters and nails a market, you know it’s been commodotized and based on the success of MSAS/DTS/etc you can tell that MSFT entered long ago and nailed it. So, if you don’t believe that the raw technology for turnings data into information is essentially commodotized then you should stop reading now. The rest will be useless to you.
What happens when software becomes a commodity? There’s usually a mid market but you start to see players emerge at two ends of a spectrum.
Commodity End (Windows, Open Office, linux, Crystal Reports):
- Hit the good side of the features curve. Definitely stay on the good side of the 80/20 rule.
- Focus on lots and lots of basic features. You’re trying to appeal to lots and lots of people. If you’re pipe isn’t 1000x bigger than the other market you are toast.
- Provide a “reasonable” quality product. To use a car metaphor, you build an automatic transmission car with manual windows. The lever to open and close the window doesn’t usually fall off and if it does, you’ve already put 100,000 miles on the car.
- Treat the user experience as one category in “Features.” Usability is something you build so that customers don’t choose the other guy over you – it’s not core to your business, you just have to provide enough for them to be successful and not hate your product.
- Sell a LOT of software. Commodity End of a market is about HIGH VOLUME (you should sell at least one or two orders of magnitude more than the experience end) – however, people looking for “reasonable commodity” products are cheap. They want low prices so this also means your MARGINs are lower. Commodity selling is about HIGH VOLUME, LOW MARGIN business. (Caveat: not always true).
Experienced Based (Mac, iPhone, Crystal XCelcius):
- The good side of the 80/20 rule still applies. Experience based doesn’t always mean 100% high end, every bell and whistle.
- Focus on features that matter to the user doing a job. If a feature is needed to help a customer nail a part of their using your product it, add it and make it better than they expect. Lacking features isn’t a bad thing if you keep adding them – for instance the iPhone was LAME feature for feature initially (no GPS, battery was a pain, etc) but users were patient.
- Provide a high quality product that is as much about using as doing. The experienced based product says that it’s not enough to have a product that does what you want, but it has to be something you ENJOY using.
- User and Experience is KING. Usability is not something that is a feature to implement, it’s the thing that informs, prioritizes and determines what features are implemented.
- Sell some software. In order to get the driving experience a user wants (BMW 700x series) they are willing to pay for it. It’s a higher margin business and there’s no secret that if someone is looking for something that both works, and they LOVE to use then it’s worth more to them. It’s a LOWER VOLUME, HIGHER MARGIN business. (Caveat: not always true – things are relative. iPod is higher margin but also high volume).
So… Let’s get back to the point on BI. I’ve built some sexy BI dashboards for customers that look great, including some recent ones based on the Open Flash Chart library. However, I come more from the Data Warehouse side of the house so more of my time is spent on ETL, incremental fact table loads, etc. I understand that you have to have a base of function/feature to have a fighting chance on the experience side.
Sexy isn’t “just sexy” if done right. When done right, Sexy is called “Great Experience.”
Experience is about creating something that people want to use. People are happier with a software product when they enjoy using it. For instance, Ted refers to Tableau as “a radically new product.” I’ve seen it and it’s a GREAT experience, with some GREAT visualization but there’s nothing REVOLUTIONARY about it except for the experience. It’s not in the cloud, it’s not scaling beyond the petabytes, it’s not even a web product (it’s a windows desktop APP). Not revolutionary, just GREAT to use.
Tableau is an up and comer for taking something commoditized (software to turn data into insight) and making it fun to use and leaving users with a desire for more. Kudos to Tableau.
What about on the commodity side – that’s where players like Pentaho come in. They’ve built something that meets a TON of needs for a TON of customers and does so at a VERY VERY compelling price (free on open source side, or subscription for companies). Recall, Pentaho is the software that I use day in and day out to help customers be successful – and they are consistently. Pentaho is earnestly improving their usability that matches up with the philosophy of Usability is a category of features. Sexy is just Sexy for the kind of business and market they are trying to build. They want to make things look nice to be usable and help people do their job well but they’re not going to spend man years on whizbang flash charts. The commodity end is a great business model – Amazon.com is pointed about their business model of “pursuing opportunities with high volume and low margins and succeeding on operational excellence.” I consider Pentaho a bit more revolutionary than Tableau – it’s 100% platform independent and the rate at which open source development clips IS REVOLUTIONARY.
Pentaho is an up and comer for taking something commoditized (software to turn data into insight) and making it easy to obtain, inexpensive to purchase, and feature rich. Kudos to Pentaho.
Both sides of the market are valid. There’s a Dell and an Apple. There’s BMW and Hyundai – both are equally important to the markets they serve and the same is true for BI as a market.
PS – I do agree with L. Wayne Johnson that there can be sexy that is “just sexy.” A whizbang flash dial behind questionable data is pretty lame, or an animation that adds nothing to the data (see this Flash pie chart for an example of a useless sexy animation) The point being that if you consider the “antee” for the BI game at “good data” then the experience/feature sets/approach is what separates the market.