I had a customer recently who had very hierarchical data, with some complicated measures that didn’t aggregate up according to regular ole aggregation rules (sum, min, max, avg, count, distinct count). Now, one can do weighted averages using sql expressions in a Measure Expression these rules were complex and they also were dependent on the other dimension attributes. UGGGGH.
Come to that: their analysts had the pristine, blessed data sets calculated at different rollups (already aggregated to Company Regions). Mondrian though, is often too smart for it’s own good. If it has data in cache, and things it can roll up a measure to a higher level (Company Companies can be rolled up to Regions if it’s a SUM for instance) Mondrian will do that. This is desirable in like 99.9% of cases. Unless, you want to “solve” your cube and just tell Mondrian to read the data from your tables.
I started thinking – since their summary row counts are actually quite small.
- What if I could get Mondrian to ignore the cache and always ask the database for the result? I had never tried the “cache=” attribute of a Cube before (it defaults to true and I work with that 99.9% of the world). Seems like setting it to false does the trick. Members are read and cached but the cells aren’t.
- What if I could get Mondrian to look to my summary tables for the data instead of aggregating the base fact? That just seems like a standard aggregate table calculation. Configure an aggregate table so Mondrian will read the Company Regions set from the aggregate instead of the fact
Looks like I was getting close to what I wanted. Here’s the dataset I came up with to test:
mysql> select * from fact_base;
+----------+-----------+-----------+
| measure1 | dim_attr1 | dim_attr2 |
+----------+-----------+-----------+
| 1 | Parent | Child1 |
| 1 | Parent | Child2 |
+----------+-----------+-----------+
2 rows in set (0.00 sec)
mysql> select * from agg_fact_base;
+------------+----------+-----------+
| fact_count | measure1 | dim_attr1 |
+------------+----------+-----------+
| 2 | 10 | Parent |
+------------+----------+-----------+
1 row in set (0.03 sec)
mysql>
Here’s the Mondrian schema I came up with:
<Schema name=”Test”>
<Cube name=”TestCube” cache=”false” enabled=”true”>
<Table name=”fact_base”>
<AggName name=”agg_fact_base”>
<AggFactCount column=”fact_count”/>
<AggMeasure name=”[Measures].[Meas1]” column=”measure1″ />
<AggLevel name=”[Dim1].[Attr1]” column=”dim_attr1″ />
</AggName>
</Table>
<Dimension name=”Dim1″>
<Hierarchy hasAll=”true”>
<Level name=”Attr1″ column=”dim_attr1″/>
<Level name=”Attr2″ column=”dim_attr2″/>
</Hierarchy>
</Dimension>
<Measure name=”Meas1″ column=”measure1″ aggregator=”min”>
</Measure>
</Cube>
</Schema>
Notice that the aggregate for Parent in the agg table is “10” and the value if the children are summed would be “2.” 2 means it agged the base table = BAD. 10 means it used the summarized data = GOOD.
The key piece I wanted to very is that if I start with an MDX for the CHILDREN and THEN request the Parent will I get the correct value. Run a cold cache MDX to get the children values:
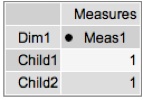
Those look good. Let’s grab the parent level now, and see what data we get:
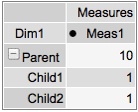
The result is 10 = GOOD! I played around with access methods to see if I could get if messed up and on my simple example it didn’t. I‘ll leave it to the comments to point out any potential issues with this approach but it appears as if setting cache=”false” and setting up your aggregate tables properly will cause Mondrian to be a dumb cell reader and simply select out the values you’ve already precomputed. Buyer Beware – you’d have to get REALLY REALLY good agg coverage to handle all the permutations of levels in your Cube. This could be rough – but it does work. 🙂 And caching – it always issues SQL so that might be an issue too.
Sample: cachetest.zip
Mondrian – you’ve been dumbed down! Take that!!!