Kettles secret in-memory database is
- Not actually secret
- Not actually Kettles
There. I said it, and I feel much better. 🙂
In most circumstances, Kettle is used in conjunction with a database. You are typically doing something with a database: INSERTs, UPDATEs, DELETEs, UPSERTs, DIMENSION UPDATEs, etc. While I do know of some people that are using Kettle without a database (think log munching and summarization) a database is something that a Kettle developer almost always has at their disposal.
Sometimes there isn’t a database. Sometimes you don’t want the slowdown of persistence in a database. Sometimes you just want Kettle to just have an in memory blackboard across transformations. Sometimes you want to ship an example to a customer using database operations but don’t want to fuss with database install, dump files, etc.
Kettle ships with a Hypersonic driver, and therefore, has the ability to create an in memory database that does (most) everything you need database wise.
For instance, I’ve created two sample transformations that use this in-memory database.
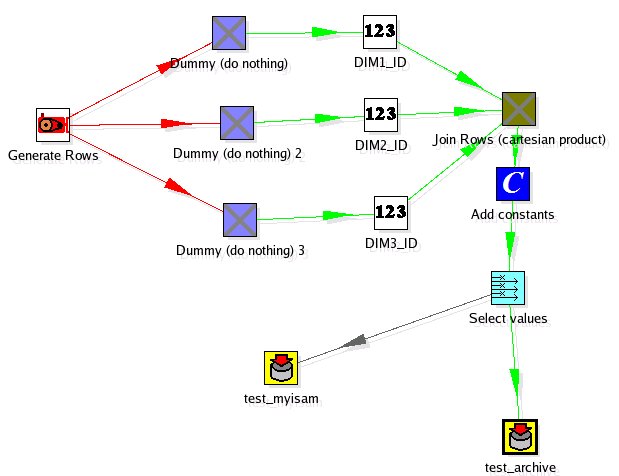
The first one, kettle_inprocess_database.ktr, loads data into a simple table:
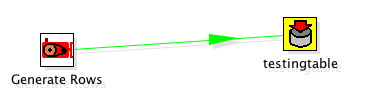
The second one, kettle_inprocess_database_read.ktr, reads the data back from that simple table:

To setup the database used in both of these transformations, which has no files, and is only valid for the length of the JVM I’ve used the following Kettle database connection setup.
I setup a connection named example_db using the Generic option. This is so that I have full control over the JDBC URL.
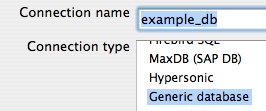
I then head to the Generic tab and input by URL and Driver. Nothing special with the driver class, org.hsqldb.jdbcDriver that is just the regular HSQLDB driver name. The URL is a little different then usual. The URL provided tells hypersonic to use a database in-memory with no persistence, and no data fil.e”
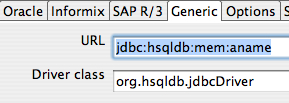
Ok, that means the database “example_db” should be setup for the transformations.
Remember, there is NOTHING persistent about this database. That means, every time I start Kettle the database will have no tables, no rows, no nothing. Some steps to run through this example.
- Open kettle_inprocess_database. “Test” the example_db connection to ensure that I / you have setup the in-memory database correctly.
- Remember, nothing in the database so we have to create our table. In the testing table operator, hit the SQL Button at the bottom of the editor to generate the DDL for this smple table.
- Run kettle_inprocess_database and verify that it loaded 10 rows into testingtable.
- Run kettle_inprocess_database_read and verify that it is reading 10 rows from the in-memory table testingtable.
I should note that using this approach isn’t always a good idea. In particular there’s issues with memory management, thread safety, it definitely won’t work with Kettles clustering features. However, it’s a simple easy solution for some circumstances. Your mileage may vary but ENJOY!