Like all great open source products, Pentaho Data Integration (Kettle) is a functional product in and of itself. It has a very productive UI and delivers exceptional value as a tool in and of itself. Most pieces of the Pentaho platform reflect a desire to keep the large communities around the original projects (Mondrian, JFree, etc) engaged; they are complete components in and of themselves.
When used together their value, as it relates to building solutions increases and exceeds their use independently. I’ll be the first to admit that Pentaho is still fairly technical, but we’re rapidly building more and more graphical interfaces and usability features on top of the platform (many in the open source edition, but much is in the professional edition). Much of this work involves making the "whole" (Pentaho) work together to exceed the value of the pieces (Mondrian, Kettle, JFree, …).
A few things immediately come to mind of why Pentaho and Kettle together provide exceptional value as compared to used individually or with another open source reporting library:
- Pentaho abstracts data access (optionally) from report generation which gives report developers the full POWER of Kettle for building reports.
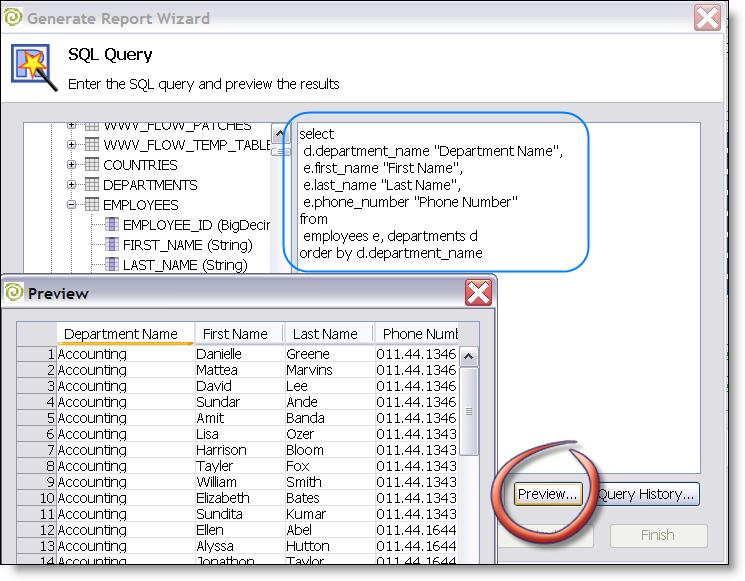
There are some things that are tough, if not downright impossible to do in SQL. Ever do an HTTP retrieval of an XML doc, slurp in a custom lookup from Excel, do a few database joins and analytical calculations in a SQL statement? I bet not. Report developers are smart data dudes; having access to a tool that allows them to sort/pivot/group/aggregate/lookup/iterate/list goes on and on/etc empowers report developers in a way that a simple "JDBC" or "CSV" or "XQuery" alone can accomplish.
How is this made possible?
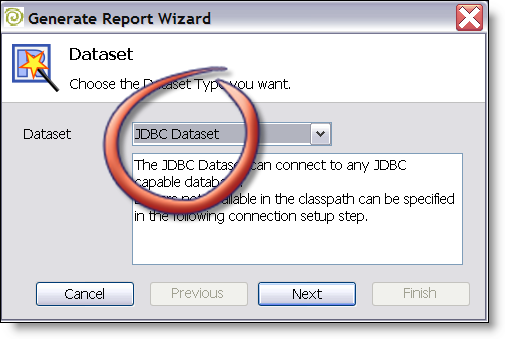
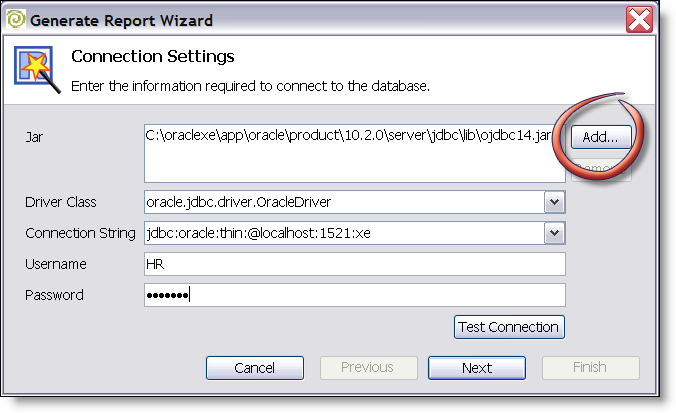
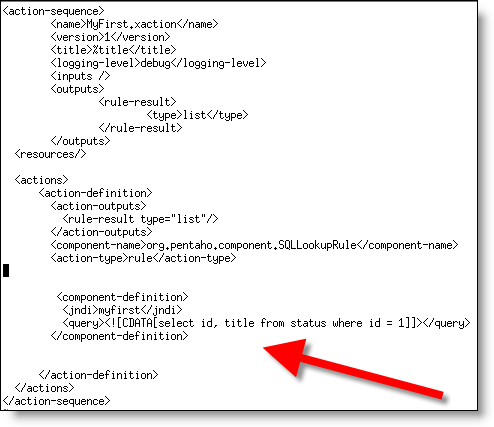
Pentaho abstracts (optionally, it isn’t forced on customers) the data retrievals to lookup components. This allows BI developers to use either a SQL lookup (DB), XQuery lookup(XML), MDXLookup (OLAP), or Kettle lookup (EII) to populate a "ResultSet." Here’s the beauty; reports are generated off a result set instead of directly accessing the sources. This means that a user can use the same reporting templates, framework, designer, etc and feed/calculate data from wherever they desire. Truly opens a world of possibiliy where before there was "just SQL" or "ETL into DB tables." - Ability to manage the entire solution in one place
Pentaho has invested greatly in the idea of the solution being a set of "things" that make up your BI, reporting, DW solution. This means you don’t have ETL in one repository, reports managed somewhere else, scheduling managed by a third party, etc. It’s open source so that’s obviously a choice, but we can add much value by ensuring that someone who has to transform data, schedule that, email and monitor, secure, build reports, administer email bursting, etc can do some from one "solution repository." Managing an entire BI solution from one CVS repository? Now that’s COOL (merge diff/patch anyone?).
- Configuration Management
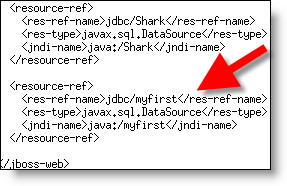
Kettle is quite flexible; the 2.3.0 release extends the scope and locations where you can use variable substitution. From a practical standpoint this means that an entire Chef job can be parameterized and called from a Pentaho action sequence. For instance, because you can do your DW load from inside Pentaho action sequences that means you can secure it, schedule it, monitor it, initiate it from an outside workflow via web service, etc. In one of my recent Kettle solutions ALL OF THE PHYSICAL database, file, and security information was managed by Pentaho so the Kettle mappings can literally be moved from place to place and work inside of Pentaho.
- Metadata and Additional Integration
Pentaho is investing in making the tools more seamless. In practice (this is not a roadmap or product direction statement) this means being able to interact with tables, connections, business views inside of Kettle in an identical (at least similar way) in the report designer. For example, if you’ve defined the business name for a column to be "Actual Sales" Kettle and the Report Designer can now key off that same metadata and present a "consistent" view to the report/ETL developer instead of knowing that "ACT_SL_STD_CURR" is actual sales.
Another example is the plans to do some additional Mondrian/Kettle integration to make the building of Dimensions, Cubes, and Aggregates easier.