For those that don’t know the reference between lilac suit and Pete-s, just google it. 🙂 Doesn’t really matter though when compared with the great set of articles that my friend Pete-S is pumping out from the other side of the Atlantic.
Pete has in the trenches practical knowledge building BI and DW systems. He’s both sharp, and practical (that’s rare you know!). He’s running a series DW Wisdom and it’s some very useful content.
I like that Pete is comfortable enough with his own skills/abilities to question the "age old wisdoms" of DW. Even if they are found to be true it’s good to see some real scientific "assumption breaking" to prove/disprove reality.
-
Use as many small disks as possible – a 1TB disk would be a bad idea for a system that inherently reads large volumes of data, everything would go through a single IO point.
-
Keep all the OLTP tables separate from the DW systems; OLTP has lots of small, fast transactions, DW has slower, big reads. DW loves bitmap indexes, OLTP hates them.
- Use high degrees of parallel processing
But are these truths still valid?
Comparison of OLTP vs DW(OLAP-esque): Great reference table:
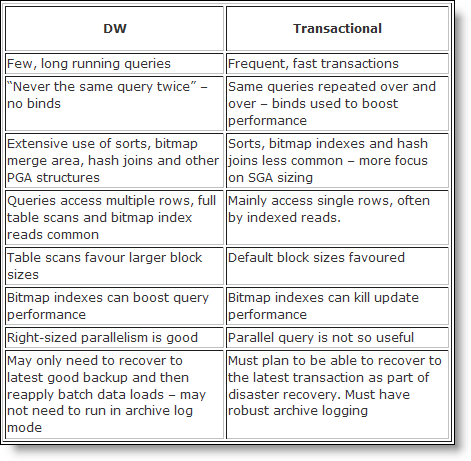
When people found that their transactional systems were unsuited for BI reporting (perhaps because of the performance impact of running BI on a transactional system, or the transactional system did not hold all of the data required for reporting) they started to look towards dedicated data warehouses.
Enterprise DW moves away from the tactical departmental “point solutions” and into something that fits with strategic aspirations of the enterprise. On the face of it having a single solution across the enterprise as distinct advantages:
-
there is a single, consistent model of enterprise data
- there is less duplication of data across the enterprise
- it is possible to construct a security model such that the right people see all of the data that allows them to their jobs but not the information that is too sensitive for their job role
- the origins of all of the business data can be traced back to source
In fact these aims are so laudable that they have been hijacked by other IT disciplines such as master data management, risk and compliance management, and business process reengineering.
I can’t agree with Pete more: A staging, 3NF warehouse, and then presentation layer (marts) I think is a very practical way to seperate concerns, and avoid tight coupling between source and reports. A la Corporate Information Factory.
For a long while I have favoured a three section data warehouse design: a staging area where raw fact and reference data is validated for referential integrity, a third-normal form layer to hold the reference data and historical fact, and finally a presentation layer to hold denormalised reference data and aggregated fact. The staging layer is ‘private’ to the data warehouse but user query access (subject to business security rules) to other layers is permitted. In some cases it will not be possible to use a denormalised layer; but if you can use one, you should.
As mentioned yesterday, the staging area of the data warehouse has three functional uses:
-
It is the initial target for data loads from source systems
Optionally, it may also be where the logic to transform incoming data is applied.
Great series Pete! Now if only this were in a book that I could tell all my blog readers and colleagues to purchase! 🙂


